Data Glossary 🧠
Search
What is a Semantic Warehouse
It incorporates best practices espoused by Bill Inmon for robust, scalable warehouse design built for the cloud as an abstraction of the Modern Data Stack with ata modeling at its core.
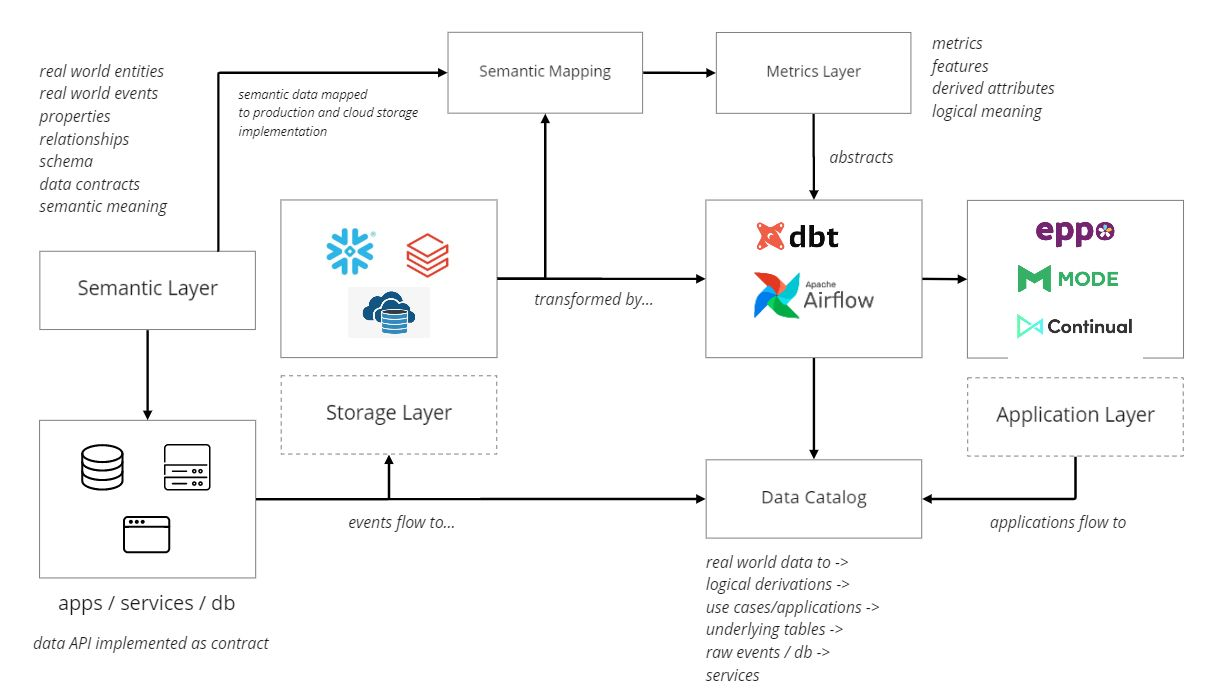 Illustrating the Semantic Warehouse from
Chad Sanderson on LinkedIn
Illustrating the Semantic Warehouse from
Chad Sanderson on LinkedIn
Chad Sanders first introduced the term in this LinkedIn post. Some defining features:
- Data as a product and capturing the natural world through events instead of batch processing with a clear defined schema
- Data Contract as a foundation to introduce contracts to its underlying source tables.
- Collaborative, peer-reviewed data modeling.
- Centralized metrics with a Metrics/Locical Layer allow collaborative data modeling between the business and the (data) engineers and abstract away the complexity of the data stack.
- Built-in incentives with semantics and modeling are required to generate good Data Products.
The semantic warehouse tries to solve the following problems:
- The Modern Data Stack (MDS) is a good set of tools for building things, but they do not help ensure that what is being built is high quality.
- Most data architectures and data foundations are not scalable. The first version of data infrastructure (typically set up by engineers or junior data devs) is never refactored because it is tough to do so
- Producers do not (but should) own data quality. Data Engineers should not be middle-men caught in the cross-fire of consumers
- Semantics and context are missing. Data devs spend days to weeks just trying to understand what data we have, what it means, how it maps to services, and whether data can be trusted
- Data modeling was not a first-class citizen. Modeling was challenging to do (because of #4) and, in some cases, impossible, thanks to data simply being missing.
- Our Data Warehouse did not reflect the real world. Instead, it was a dumping ground for production services and 3rd party APIs.
- A lack of interoperability due to tools not ‘speaking the same language.’ We have multiple products which each require their distinct modeling environment and no shared understanding of business concepts
- Data Governance is critical, but businesses will reject it if it becomes a bottleneck. We cannot scale our data team horizontally with the complexity
See also Semantic Layer and Data Contract.